
When agents fail: compounding errors in organisational systems
How a probabilistic model of Chinese whispers can kill a system of A+ agents.

There’s a dirty little secret about multi-step agentic systems that nobody particularly wants to talk about. It’s not that they fail - of course they fail, everything fails - it’s that they fail in ways that compound mercilessly, and that this compounding is a feature of the mathematics, not a bug in the implementation. You cannot engineer your way out of it. You can only manage it.
The maths of sequential failure
Let’s start with something deceptively simple. Imagine you have a five-step process, and each step has a 95% success rate. That sounds pretty good, doesn’t it? 95% is an A grade. It’s the kind of number you’d be happy to show a stakeholder.
The naive calculation goes like this: if each step fails independently, your overall system success rate is:
0.95 × 0.95 × 0.95 × 0.95 × 0.95 = 0.774
That’s 77.4%. Your A-grade components have produced a C-grade system. Nearly a quarter of your runs will fail somewhere along the chain.
But this calculation hides a crucial assumption: that once a step fails, the pipeline is dead. The failure is absorbing - there’s no recovery. This is one model of failure, and it’s worth examining. But it’s not the only one, and the differences matter enormously for how you design and manage agentic systems.
A better model: sticky failures
Let’s be more careful. Consider a Markov chain where each step can either succeed or fail, and the probability of failure depends on what happened in the previous step:
P(fail | previous step succeeded) = 5% - this is your baseline error rate
P(fail | previous step failed) = ??? - this is the interesting parameter
That second probability captures something important: how “sticky” are failures? When something goes wrong, does the system tend to recover, or does it tend to stay wrong?
Let’s work through the maths for different values:
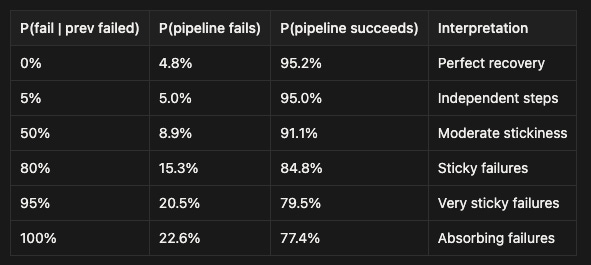
Look at that last row. When P(fail | previous failed) = 100%, we recover our naive calculation of 77.4% success. The “independent steps” model that everyone uses actually assumes perfectly absorbing failures - once something goes wrong, it stays wrong forever.
But look at the other rows. If your system has even moderate recovery capability - say, a 50% chance of getting back on track after a failure - your success rate jumps from 77.4% to 91.1%. If failures are truly independent (5% failure rate regardless of history), you get 95% success - the same as a single step.
What this means for real systems
This reframing changes everything. The question isn’t just “how reliable is each step?” but “how sticky are failures?”

Absorbing failures (P ≈ 100%) are what you get when errors propagate invisibly. The agent makes a mistake in step 2, produces plausible-looking but wrong output, and every subsequent step builds confidently on that wrong foundation. By step 5, you’re miles from where you should be, but nothing has explicitly “failed”. This is the nightmare scenario, and it’s distressingly common in LLM-based systems where errors are semantic rather than syntactic.
Sticky failures (P ≈ 80-95%) happen when errors are somewhat visible but hard to recover from. Perhaps the system notices something is off but lacks the context to fix it. Perhaps retry logic helps sometimes but not always. This is probably where most real agentic systems live.
Moderate stickiness (P ≈ 50%) is what you get with decent error handling - validation steps that catch some problems, retry mechanisms that work some of the time, or agents that can sometimes recognise and correct their own mistakes.
Recovery (P < 5%) is the dream: a system that actively self-corrects, where a failure at one step triggers compensating behaviour that gets things back on track. But let’s be clear - it’s truly a dream - if in reality you can manage this kind of recovery rate, it means your problem was likely solvable without using agents in the first place!
The leverage is in the stickiness
Here’s the counterintuitive insight: improving individual step reliability from 95% to 99% is extremely hard (Pareto principle) and gives you modest gains. But reducing failure stickiness - building systems that can recover from errors - can improve overall reliability even with the same per-step failure rate.
Consider: a system with 95% per-step reliability and 50% failure stickiness achieves 91.1% overall success. To get the same 91.1% success rate with absorbing failures, you’d need 98.15% per-step reliability - cutting your error rate from 5% to 1.85%, a reduction of nearly two-thirds.
Put another way: adding strong recovery capability is equivalent to making each step 2.7 times more reliable. The intervention isn’t “make fewer mistakes” - it’s “recover from mistakes faster”. And the latter is often more achievable than the former.
Why you still can’t fully fix this
Before you get too excited, let me temper expectations. Reducing failure stickiness is powerful, but it’s not magic.
First, achieving low stickiness is genuinely hard. It requires your system to detect that something has gone wrong (not easy when errors are semantic), diagnose what went wrong (harder still), and take corrective action (hardest of all). Most “retry” logic just re-runs the same step with the same inputs, which does nothing if the failure was deterministic.
Second, the baseline failure rate still matters. Even with perfect recovery (P(fail|fail) = 0%), your success rate is capped at around 95% for our five-step system. You can’t recover from a failure in the final step. The maths is forgiving but not infinitely so.
Third, you’re often choosing your poison. Systems with absorbing failures (high stickiness) fail more often, but when they fail, you often know where things went wrong - the error is localised to the step that failed. Systems with good recovery might succeed more often, but when they do fail, the error could have originated anywhere and been partially corrected multiple times. Debugging becomes archaeology.
Managing what you can’t fully fix
So what do you actually do? The new framing suggests different interventions:
1. Measure stickiness, not just step reliability. Most teams obsess over per-step success rates. But the table above shows that stickiness is often the bigger lever. Track how often a failure at step N is followed by a failure at step N+1. If that number is high, you have a stickiness problem, and no amount of per-step optimisation will save you.
2. Make failures visible and recoverable. The difference between 77% and 91% success comes from the system’s ability to detect and recover from errors. This means validation at every step, clear error signals (not swallowed exceptions), and - crucially - the ability to do something different when an error is detected. Retry logic only helps if the retry has a chance of succeeding.
3. Design for graceful degradation, not just success. If your system has sticky failures, at least make them informative. Capture state at each step. Log aggressively. Make it possible to diagnose where things went wrong, even if you can’t automatically fix them.
4. Consider the stickiness-debuggability tradeoff. Systems with low stickiness are more reliable but harder to debug when they do fail. Systems with high stickiness fail more often but failures are more localised. There’s no universally right answer - it depends on whether you’re optimising for throughput or for diagnosability.
5. Budget for the failure rate you actually have. Whatever your stickiness level, calculate your actual system success rate using the model above. If your five-step system has 95% per-step reliability and 80% stickiness, you’ll succeed about 85% of the time. Build that into your capacity planning, your SLAs, and your user experience.
The uncomfortable conclusion
Multi-step agentic systems fail. They fail more often than their components would suggest, and the mathematics of sequential composition is unforgiving. But the picture is more nuanced than the naive “multiply the probabilities” model suggests.
The key insight is that failure stickiness matters as much as failure rate. A system that can recover from errors - even imperfectly - dramatically outperforms one where errors are absorbing. The intervention isn’t always “make fewer mistakes”; sometimes it’s “recover from mistakes faster”.
This doesn’t make the problem easy. Building systems with low failure stickiness requires genuine engineering effort: detection, diagnosis, and correction at every step. But at least now you know where to look.
Sequential pipelines fail at rates determined by two factors: per-step failure probability and failure stickiness (how likely a failure is to persist). A five-step process with 95% step reliability and absorbing failures (stickiness = 100%) succeeds only 77% of the time. But with 50% stickiness, success jumps to 91%. The naive “multiply the probabilities” model implicitly assumes perfectly absorbing failures - often the worst case.
The practical implication: measure and reduce stickiness, not just per-step reliability. Build systems that detect and recover from errors. And budget for the failure rate you actually have, not the one you wish you had.